


中小企業から大手企業まで、累計100社以上のAI・DX支援実績があります。
SEO/AIO対策、広告運用、AI開発、サイト改善、業務効率化まで、必要な施策を「定額」で代行します。
「マーケに詳しい人が社内にいない」
「AIやAIOも気になるが、何から始めればいいかわからない」
そんな企業様に、負担の少ない形でプロの知見をご提供します。
本記事を読めば、月あたり数十時間の問い合わせ対応工数を削減しつつ、従業員の自己解決率を2倍以上に引き上げるAI自動応答の設計手順を、失敗パターンを回避しながら再現できます。
FAQ型チャットボットの限界とRAG型AIの設計ポイントを、具体的な評価指標と併せて解説します。
社内問い合わせ自動化にAIが求められる背景と課題の構造
総務・情シス部門の「問い合わせ対応に追われてコア業務が進まない」という悩みは、従業員50名を超えた時点から急速に深刻化します。AI自動応答が注目される背景には、単なる省人化ニーズではなく構造的な要因があります。
総務・情シス部門が問い合わせ対応に時間を取られる原因
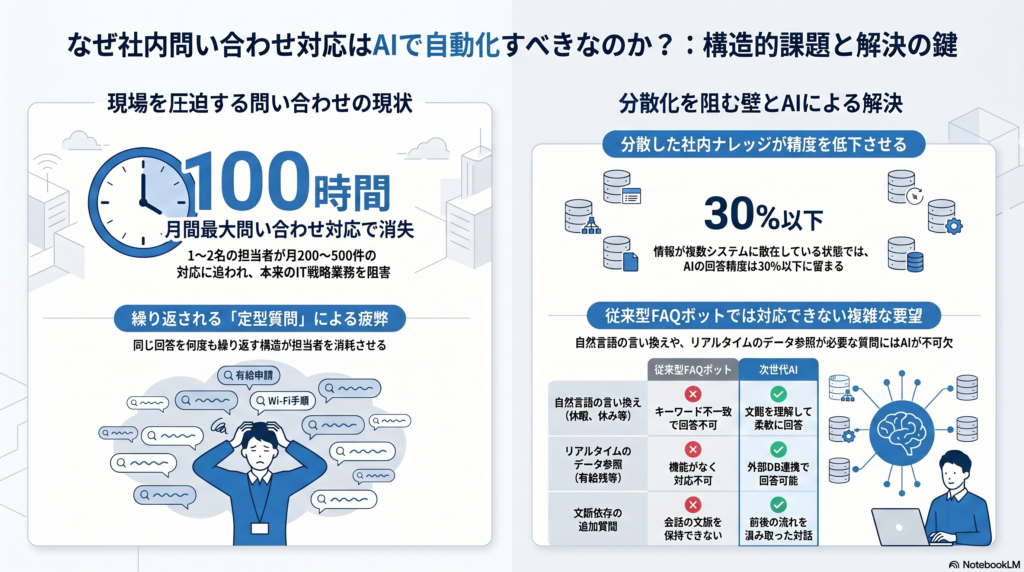
従業員50〜300名規模の企業で、総務・情シス担当者1〜2名が月に受ける問い合わせは200〜500件にのぼります。1件あたり平均10〜15分の対応時間を要するため、月あたり40〜100時間が問い合わせ対応だけで消える計算になります。
さらに厄介なのは、同じ質問が繰り返し発生する点です。「有給の申請方法」「Wi-Fiのパスワード」「VPN接続手順」といった定型的な質問が、新入社員の入社や人事異動のタイミングで毎回発生します。担当者は同じ回答を何度も繰り返すことに疲弊し、本来の制度設計やIT戦略などのコア業務に集中できなくなります。
社内ナレッジの分散が自動化を阻む構造的な問題
問い合わせ自動化が進まない最大の要因は、社内ナレッジが複数のシステムに分散していることです。就業規則はSharePoint、IT手順書はGoogle Drive、製品マニュアルはNotion、紙の規程集は総務部の棚、といったように情報の置き場がバラバラというケースが典型的です。
検索対象が一元化されていないと、AIが参照できる情報ソースを揃えられず、回答精度が出ません。この「ナレッジの棚卸し」を後回しにしてAIツールだけを先に導入すると、高額なAIツールを導入したのに回答精度が30%以下に留まるという失敗に直結します。
FAQ型チャットボットでは対応しきれない問い合わせの特徴
従来のFAQ型チャットボットは、事前登録した「質問と回答のペア」をキーワードマッチで返す仕組みです。典型的な質問には対応できますが、以下のタイプの問い合わせには対応できません。
| 問い合わせのタイプ | 具体例 | FAQ型で対応できない理由 |
|---|---|---|
| リアルタイムDB参照が必要 | 「私の有給残日数は?」「今月の経費精算締め日は?」 | 従業員固有のデータをリアルタイム取得する機能がない |
| 自然言語の言い換えが多い | 「休暇取りたい」「休みたい」「有給使いたい」 | キーワード一致でブレに追従できない |
| 文脈依存の追加質問 | 「さっきの件でもう一つ聞きたい」 | 会話文脈を保持できない |
| 複数条件を組み合わせる質問 | 「在宅勤務手当は子育て中の社員も対象?」 | 条件分岐の複雑さに耐えられない |
こうした問い合わせは、キーワードマッチではなく自然言語理解と外部データ連携が可能なAIでないと解決できません。
社内問い合わせ自動化AIの仕組みと導入パターン比較
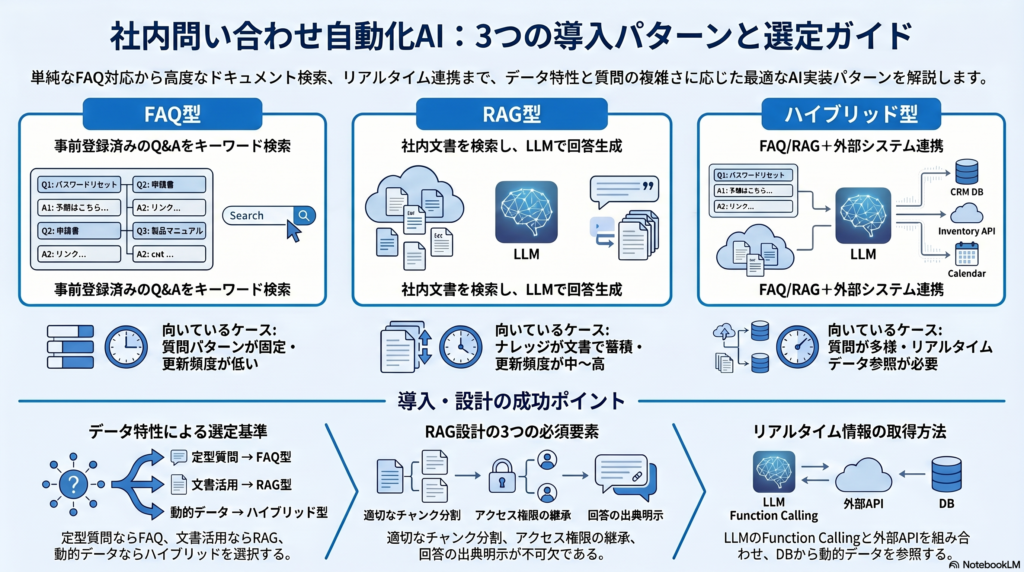
AI自動応答の実装パターンは、大きく3つに整理できます。
FAQ型チャットボット・RAG型AI・ハイブリッド型の違いと選定基準
それぞれの特徴と適した用途を比較表で整理します。
| 実装パターン | 仕組み | 対応できる質問 | 初期構築工数 | 向いているケース |
|---|---|---|---|---|
| FAQ型チャットボット | 事前登録したQ&Aペアをキーワード検索で返す | 典型的な定型質問のみ | 小(数十件の登録で開始可) | 質問パターンが固定・ナレッジ更新頻度が低い |
| RAG型AI | 社内ドキュメントをベクトル検索し、LLMで回答を生成 | 自然言語・言い換えに強い | 中(ドキュメント整備が必要) | ナレッジが文書で蓄積済み・更新頻度が中〜高 |
| ハイブリッド型 | FAQ型+RAG型を併用、DB参照も組み合わせる | ほぼすべての社内質問 | 大(各コンポーネントの連携設計が必要) | 質問の多様性が高く・リアルタイムデータ参照が必要 |
選定基準としては、更新頻度の低い定型質問が8割以上ならFAQ型・ナレッジ文書が整備済みで自然言語対応が必要ならRAG型・有給残日数や経費精算など動的データが絡むならハイブリッド型という切り分けが実用的です。
RAG型AIで社内ドキュメントを検索対象にする際の設計ポイント
RAG(Retrieval-Augmented Generation)は、社内ドキュメントをベクトルDBに登録し、質問に関連する箇所だけを検索してからLLMに回答を生成させる仕組みです。設計で外せないポイントは以下の3つです。
第一に、ドキュメントのチャンク分割粒度です。長すぎると関連性の低い情報がノイズになり、短すぎると文脈が切れて正確な回答ができません。一般的には500〜1,000文字(日本語)が目安で、章・節・見出し単位で分割する方式が安定します。第二に、アクセス権限の継承です。
人事データや給与情報といった機密ドキュメントは、元ファイルの権限をRAG検索の結果にも反映する必要があります。権限設計を後回しにすると、情報漏洩リスクが発生します。第三に、検索結果の出典表示です。AIの回答が正しいかを人間が検証できるよう、回答の根拠となったドキュメント名・ページ・該当箇所を明示する設計が必須です。
リアルタイムDB参照が必要な問い合わせへの対応方法
「有給残日数」「今月の経費精算締め日」「自分の健康診断予約状況」といった質問は、人事DB・勤怠管理システム・予約管理システムにリアルタイムで問い合わせる必要があります。RAGだけでは対応できないため、LLMのFunction Calling機能と外部APIの組み合わせで実装します。
具体的には、質問内容をLLMが解析し、「有給残日数を問い合わせている」と判定した場合は人事APIを呼び出す、「経費締め日」なら経理システムのAPIを呼び出すという分岐設計です。この構成により、ドキュメントに書かれていない動的データにも回答できる自動応答が実現します。
社内問い合わせ自動化AIの導入で失敗する3つのパターン

多くの企業がAI自動応答の導入に失敗するのには、共通するパターンがあります。
ナレッジソースの一元化を後回しにして精度が出ないケース
最も多い失敗パターンが、社内ナレッジの棚卸しを後回しにしてAIツールだけを先に導入するケースです。「AIは賢いから適当にドキュメントを投げ込めば答えてくれる」という期待で始めると、確実に失敗します。
実際には、SharePoint・Google Drive・Notion・紙マニュアルに分散したナレッジを同じフォーマットで収集・正規化するだけで数週間かかります。さらに、古いバージョンと最新バージョンが混在している、同じ内容が複数ドキュメントで矛盾している、といった状態を解消しないと回答精度が安定しません。ナレッジの一元化に全工数の40〜60%を割く覚悟がないと、導入後に使われなくなります。
PDFの表組み・画像内テキストの取り込み不備で誤回答が頻発するケース
社内マニュアルや就業規則の多くはPDFで配布・保管されていますが、RAGがPDFを取り込む際に問題が発生しやすいポイントがあります。表組み・画像内テキスト・手書きメモ付きPDFは、単純なテキスト抽出ではレイアウトが崩れたり、画像内の文字が取り込まれなかったりします。
たとえば、就業規則の「休暇の種類と日数」が表形式で記載されている場合、通常のPDF抽出では「年次有給休暇 10日 20日 15日 25日」のように行と列が混在した文字列になり、勤続年数ごとの日数が正しく紐付かない状態で取り込まれます。
AIはこの状態のテキストから推論するため、誤回答の温床になります。対策として、AI-OCRと表構造認識を組み合わせた前処理が必要です。
回答精度の評価基準を設計せず導入後に放置されるケース
導入前に、「正答率・フォールバック率・未回答率の目標値」を定義しないと、導入後に運用が止まります。AIの回答が正しいのか・誤っているのかを測る物差しがないと、改善サイクルが回らず、数ヶ月後には「使えない」と判断されて放置される結末になります。
評価基準の設計は、導入前の要件定義フェーズで必ず決める必要があります。次章で具体的な指標を解説します。
社内問い合わせ自動化AIを定着させるための運用設計
導入後の運用設計までセットで組み立てないと、AI自動応答は定着しません。
正答率・フォールバック率・未回答率の評価指標と改善サイクル
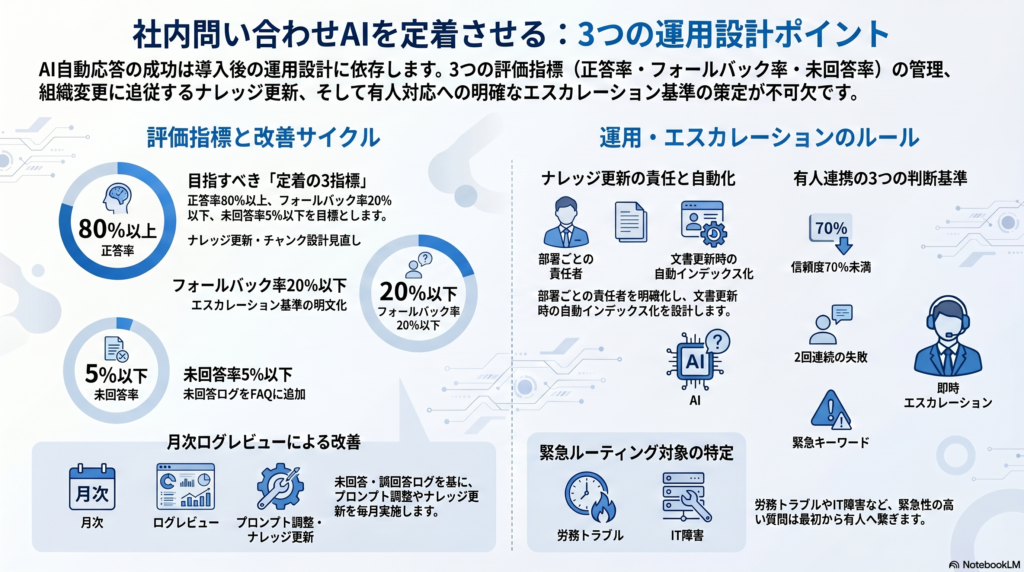
定着のために最低限追うべき3つの指標は以下の通りです。
| 指標名 | 定義 | 目標値の目安 | 改善の方向性 |
|---|---|---|---|
| 正答率 | AIの回答が正しかった割合 | 80%以上 | ナレッジの更新・チャンク設計の見直し |
| フォールバック率 | AIが有人対応にエスカレーションした割合 | 20%以下 | エスカレーション基準の明文化 |
| 未回答率 | 質問に答えられず放置された割合 | 5%以下 | 未回答ログを教師データとしてFAQ追加 |
月次でこれらの指標をレビューし、未回答・誤回答のログからナレッジ更新・チャンク再設計・プロンプト調整を回すのが改善サイクルの基本形です。ログを記録せずに指標だけ定義しても、改善は進みません。
就業規則改定や組織変更に追従するナレッジ更新フローの設計
社内ルールは年に数回改定されるのが通常です。就業規則の改定、組織変更、新しい福利厚生制度の導入が発生するたびに、AIの参照ナレッジも更新が必要です。
更新フローの設計ポイントは2つあります。第一に、ナレッジ更新の責任者と更新タイミングを明確化します。就業規則なら人事部、IT手順書なら情シス、といった形で「どの文書を誰が更新するか」を対応表にして残します。第二に、更新後のAI再インデックス処理を自動化します。ドキュメントが更新されたら自動でベクトルDBに再登録する仕組みを設計しないと、更新が追いつかずAIの回答が古いまま放置されます。
AI自動応答と有人対応のエスカレーション基準の決め方
AIで答えきれない質問は、適切なタイミングで有人対応にエスカレーションする必要があります。判断基準を決めずに「AIが答えられなかったら全部人間に回す」という設計にすると、フォールバック率が40〜60%に達し、自動化の効果が大幅に減ります。
推奨する基準は以下の3つです。第一に、AIの回答信頼度スコアが70%未満の場合は自動エスカレーション。第二に、2回以上AIが不十分な回答をした場合は有人対応に切り替え。第三に、「人事への異議申し立て」「労務トラブル」「IT障害」などの緊急性が高いキーワードを含む質問は最初から有人対応にルーティングします。
【実務で起きた課題】ナレッジ分散とPDF表組み問題でAI精度が30%に留まった事例と解決法
SharePoint・Google Drive・紙マニュアル分散で検索対象が揃わなかった問題
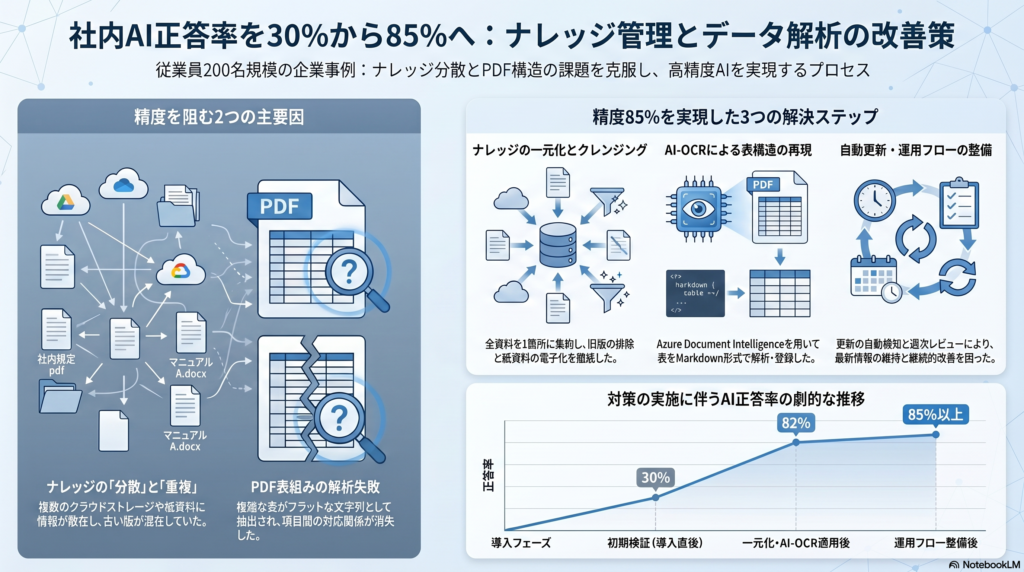
私がある従業員200名の企業で社内問い合わせAIの導入支援を行った際、初期検証で正答率がわずか30%に留まりました。原因を調査すると、ナレッジの分散が最大の問題でした。
就業規則は総務部が管理するSharePoint、IT手順書は情シスがGoogle Drive、製品マニュアルは開発部がNotion、福利厚生の規程集は紙ファイルで総務の棚に保管、という状態でした。さらに、SharePoint上の就業規則には2020年版と2023年版が同居しており、AIがどちらを参照するかで矛盾した回答をするという状況でした。
対応として、最初の1ヶ月をナレッジ一元化作業に充てました。全ドキュメントをGoogle Driveの1つのフォルダに集約、旧バージョンはアーカイブフォルダに移動、紙マニュアルは総務担当者がスキャン&AI-OCRで電子化、という手順で揃えました。
PDFの表組みが崩れてAIが「年次有給は10日」と誤回答した問題
一元化後も誤回答が残りました。最も多かったのが、「年次有給休暇の付与日数を聞くと常に10日と答える」という誤りです。原因を調べると、就業規則PDFに記載された以下のような表が、抽出時に崩れていました。
| 勤続年数 | 付与日数 |
|---|---|
| 6ヶ月経過 | 10日 |
| 1年6ヶ月 | 11日 |
| 2年6ヶ月 | 12日 |
| 6年6ヶ月以上 | 20日 |
通常のPDFテキスト抽出では、この表が「勤続年数 付与日数 6ヶ月経過 10日 1年6ヶ月 11日…」という1行のフラット文字列になり、「勤続年数」と「付与日数」の対応関係が壊れてしまいます。AIは先頭の数字10日を見て「常に10日」と回答していました。
対応として、AI-OCR(Azure Document Intelligence)で表構造を認識し、Markdownテーブル形式でベクトルDBに登録する前処理を追加しました。これにより、AIは「勤続2年6ヶ月なら12日」といった正確な回答を返せるようになり、正答率が30%から82%に改善しました。
導入後のナレッジ更新フロー整備で精度を維持した方法
最後の課題は、導入後の精度維持でした。導入3ヶ月後に就業規則が改定された際、更新が反映されず古い情報で回答する事態が発生しました。
対策として、以下のフローを整備しました。ナレッジ更新の責任者をドキュメントごとに対応表で明文化、Google Drive上のドキュメントが更新されたらCloud Functionsが自動検知してベクトルDBを再インデックス、未回答・低信頼度スコアの質問を週次でレビューしてナレッジ追加の要否を判定、という3点です。この運用により、正答率を継続的に85%以上に維持できています。
まとめ
社内問い合わせ自動化AIの成功は、ツール選定ではなくナレッジ設計と運用フローで決まります。FAQ型チャットボットの限界を理解し、RAG型AIとDB連携を組み合わせたハイブリッド構成で、典型的な質問から動的データを要する質問まで幅広く対応できる仕組みを目指しましょう。
導入を成功させる順序としては、最初にナレッジの棚卸しと一元化、次にPDF表組み・画像内テキストの前処理設計、最後に評価指標と更新フローの整備、という流れが最も失敗が少ない進め方です。「AIツールを買えば解決する」ではなく「ナレッジ設計×AI×運用フロー」の三位一体で考えることが、定着する自動応答の条件です。
AIzenでは、社内問い合わせの構造分析から、RAG型AI・ハイブリッド型自動応答の買い切り型ツール開発まで一貫して対応しています。ナレッジ分散の解消・PDF前処理・評価指標設計といった実装で失敗しがちなポイントも設計段階から支援いたします。









コメント